



Photo by Debby Hudson on Unsplash
Unlocking the Basics: Key Concepts and Practical Applications - Part I
Week1


Week 1 focuses on introducing fundamental terms and essential knowledge crucial for all learners before embarking on the course. This introduction will be divided into two or possibly three parts.
Article Outline.:
Big Data - What is it Anyway?
Why Go Distributed? Advantages Over Monoliths
Must-Haves for a Big Data System
Overview of Hadoop
Big Data
Words often wear different hats, and "Big Data" is no exception. In simple terms, big data is just an enormous amount of information. While this definition holds true in plain English, the technical definition aligns closely with this straightforward meaning. IBM, the tech giant, came up with a cool definition, originally consisting of 3 V's and later expanded to 5 V's, serving as the current standard in the field.:
Volume: Describes the sheer amount or size of data, usually measured in bytes ranging from terabytes to petabytes.
Velocity: Not the speed of light, but the speed at which the system generates, receives and processes data over a period of time.
Veracity: It's about the quality of data – is it accurate, or does it need some cleaning up before we use it?
Variety: Encompasses the diverse forms of data the systems receive as input, spanning from structured, semi-structured (e.g., JSON, XML), to unstructured (e.g., log files, images).
Structured Data
Structured data is like neatly organized information - it all follows a specific format, often presented in tables or a relational structure. Eg.: Data in RDBMSUnstructured Data
Unstructured data doesn't stick to any predetermined format. Users may format it based on their current needs, or more often, it's stored in its raw, unaltered state. Eg.: log files, images, videoSemi- Structured Data
Semi-structured data sits between structured data and unstructured data. Semi-structured data cannot be considered fully structured data because it lacks a specific relational or tabular data model. Despite this, it does include metadata that can be analyzed. Eg.: JSON,XML- Value: The ultimate goal of collecting and processing data is to derive value. To get something useful out of all this data – it could be right now or later. It's like asking, "Is this data worth collecting?"
Why Go Distributed? Advantages Over Monoliths
What is Monolith System.:
A single deployment unit of all the code. All the software components in a monolithic system are interdependent.
What is a Distributed System.:
A distributive system is a collection of multiple individual systems or a cluster of nodes.
Many big data systems leverage distributed system architecture due to its scalability and advantages over monolithic systems.
Key advantages include:
Scalability: Monolithic systems struggle to scale with increasing data size.
Scaling Type: Monolithic systems support vertical scaling, adding resources to a single system. After a period of time, performance benefit is not proportional to the resources added. Distributed systems, however, support horizontal scaling by adding resources to a cluster node.
Understanding traditional technologies is crucial, as they form the foundation for new technologies tailored to distributed systems.
Must-Haves for a Big Data System
A well-designed big data system has the following components.:
Distributed Storage: How vast amounts of data are stored across clusters.
Distributed Processing: How data is and will be computed across clusters.
Scalability: How the system handles and processes a significant influx of data
Overview of Hadoop
Launched in 2007, Hadoop is a framework designed to address big data problems. It encompasses an ecosystem of tools and technologies.
There are 3 core components of Hadoop.:
HDFS (Hadoop Distributed File Storage): Manages distributed storage.
MapReduce: Facilitates distributed processing.
YARN (Yet Another Resource Negotiator): Handles resource management.
Hadoop's ecosystem includes tools like Sqoop, Hive, HBase, Pig, and Oozie, each contributing unique functionalities.
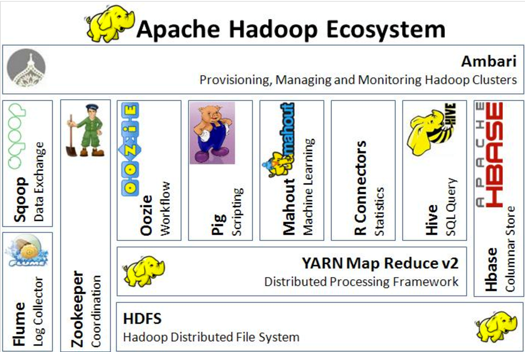
The question arises: Why learn something new when an existing ecosystem seems sufficient?
While the foundational tools provide an advantage, trends change, and challenges emerge:
MapReduce complexity and limitations.
Implementing new functionalities(even smaller ones) requires either learning or developing new tools.
Primarily suitable for on-premise solutions.
Understanding these challenges sets the stage for exploring newer solutions and advancements in the field.
If you found this article helpful or learned something new, please show your support by liking it and following me for updates on future posts.
Till next time, happy coding!